

Data Berlin #38
A full week of work in May, we are not used to it anymore


We are in the home stretch of May, which in Berlin still means random public holidays and calendar invites that say “tentative until June.” Issue 38 lands anyway.
The evening worth defending: May 28 with Adsquare for May We Talk About Data?, three talks on taming audience data at scale, evaluating ad impact in the physical world, and measuring offline campaigns when the truth is not only in the dashboard. If you have been meaning to RSVP, consider this your polite-but-firm nudge.
The rest of this issue is the usual stack, reads, jobs, things shipping, so you can skim it between whatever you are doing because half the company is still OOO and there is, finally, sun outside.
What’s new on our job board
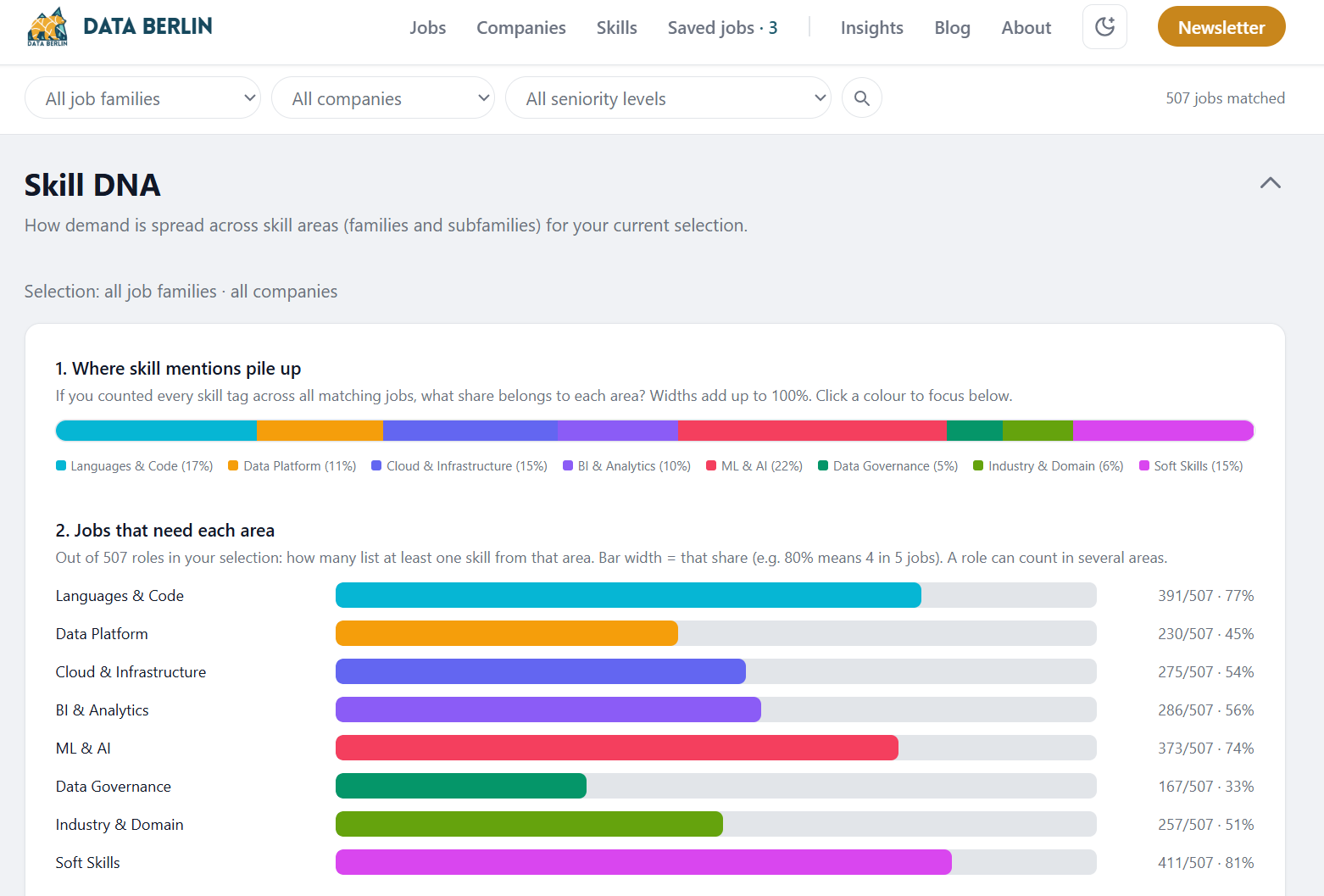
We’ve shipped a fair bit in the last few weeks. Here’s the quick tour.
Tailor your CV in one click. On any job page you’ll see “Tailor my CV to this job.” Hit it and you get a prompt ready to paste into Claude, ChatGPT, or whatever you use — company, role, and the full description already filled in. If you’ve uploaded your CV (see below) on the site, that goes in too. The prompt will start a workflow that will ask you a few questions about your applications and, maybe, skills that you have but you forgot to add. It will ask questions 1 by 1, so you can have a nice conversation with your favorite recruiter.
Save jobs, upload a CV, see how you match. There’s a proper saved-jobs page now: bookmark roles, compare them, tailor from there. You can paste a CV or upload a PDF. Everything happens on your browser, we only provide the jobs. And it’s free.
Skill DNA & insights. We added an Insights section with Skill DNA charts, which skills show up together, broken down by seniority, category, and company. You’ll see the same view on individual job pages, plus browsable skill pages with logos and short blurbs for hundreds of tools.
More jobs, cleaner listings. We’re pulling from more sources (PayPal, Eventim, Oviva, and others added recently), descriptions are more consistent, and listings carry better skill tags. We always look for new jobs on linkedin, but it’s harder and harder to find new companies, if you know that we are missing someone please inform us.
If you try the CV tailor or saved jobs, we’d love to hear what works and what doesn’t, send us an email, a slack message, or ping us at the meetup. If you have no idea what we are talking about, just visit databerlin.net.

📖Interesting Readings

Long tenure without version control, scripting, or reusable engineering makes you the local expert but hard to hire elsewhere, which matters when Berlin teams expect pipeline ownership not tribal GUI knowledge. – The 10-Year Junior
Conversational analysis only scales when questions map to a governed semantic layer instead of raw SQL, which matters because bad NLQ once killed exec trust and the semantic layer is the guardrail that makes ad-hoc questions safe again. – We need to talk more about Vibe Analytics
Green pipelines can still ship wrong numbers for days, and freshness, volume, distribution, schema, and lineage catch what job failures miss, which matters when stakeholders lose trust before any alert fires. – Data Observability: The One Thing Missing from Your Data Pipeline
A worth reminder: when revenue depends on selling information externally, quality and platform spend follow, which matters because it explains why internal dashboards stay underfunded while product-facing data teams get the real engineering budget. – The Value of Data
Rows alone are not enough for trustworthy AI; definitions and situational meaning tell people when a metric applies, which matters as agents and self-serve analytics multiply without shared context. – Context, Data, and Metadata
🚀 Shipping Now

DuckDB’s Quack protocol is the drop everyone already bookmarked: native client-server over HTTP, with multiple concurrent writers and remote
ATTACHwithout bolting on a separate database.dbt agent skills package lineage, contracts, and analytics-engineering practice so coding agents can run dbt work instead of improvising SQL from memory.
dbt’s MCP docs toolset feeds agents canonical Markdown instead of scraped HTML, so answers stay token-light and aligned with what the project actually documents.
BigQuery proxy models route simpler natural-language SQL to smaller models and reserve big LLMs for hard queries, cutting cost and latency on LLM-assisted analytics.
AlterTable Workers adds always-on agents for modeling, monitoring, and analysis on top of an AI-native data platform aimed at observability and workflow automation.
Snowflake’s Cortex Code skill routes Snowflake operations from Cursor and Claude Code to the Cortex Code CLI so agents use Snowflake-specific tooling in headless mode.
☕ Upcoming Meetups & Events

May 26 — Women Techmakers Berlin · AI & tech career with SPICED 🐍
May 27 — AI Agent Builders Berlin · powered by Dataiku 🛰️
May 28 — Tech Europe · Applied AI Conf Berlin 🤖
May 28 — Data Berlin · May We Talk About Data? 🐻
Jun 4 — Berlin Startup School · AI Prototyping: idea to app 🤖
Jun 16 — AI for Non-Techies · AI for Non-Techies 🧠
💼 This Week’s Job Picks

📊 Data Analyst
Consultant - Healthcare Data Analytics (m/f/d) – Statista → Apply
Data Analyst – Deel → Apply
Full Stack Engineer - Analytics (f/m/d) – Contentful → Apply
And more here.
📈 Analytics Engineer
Senior Data Analytics Engineer (m/f/d) – adsquare 🎙️ → Apply
Senior Analytics Engineer – Intercom → Apply
Data Analytics Architect (m/f/d) – Redcare Pharmacy → Apply
Principal Analytics Engineer (m/f/d) – AutoScout24 → Apply
And more here.
⚙️ Data Engineer
Senior Data Platform Engineer – Taxfix → Apply
Data Engineer (m/f/d) – Redcare Pharmacy → Apply
Growth Engineer (f/m/x) – HelloFresh → Apply
And more here.
🤖 AI / ML / LLM + Data Scientist
Senior Applied Scientist, Operations Research – Wolt → Apply
Data and AI Solution Architect (Professional Services) – Databricks → Apply
Senior Machine Learning Scientist – Intercom → Apply
And more AI/ML roles here and Data Scientist roles here.

If something here saved you a click or started an argument worth having, like this issue, leave a comment, or share it with someone who still thinks “offline measurement” is optional.
And if you can keep only one evening free this month, make it May 28, we would rather see you in the room than wonder if you only bookmarked the page between holidays.
— Data Berlin team
Thanks for the endorsement, Mucio!